

| 浩如烟海的古籍如何装进方寸大小的屏幕?北大与字节跳动联合推出古籍数字化平台 | |
| 2022-12-23 18:13:09 作者:彭丹 | |
浩如烟海的古籍如何装进方寸大小的屏幕之中,让古代文明“触手可及”?借助大数据、人工智能为代表的信息技术,古籍的整理、利用与传播迎来了新的机遇与方向,近期上线的由字节跳动与北京大学数字人文研究中心合作研发的古籍数字化平台“识典古籍”(测试版)便是一个生动案例。
该平台目前涵盖460余部经典古籍,主要来自《四部丛刊》,共计8000万字左右。与以往一些商业化古籍数字平台不同,“识典古籍”不仅免费向公众开放,还具备简繁转换、原本影像对照、全文检索、注疏辅助等一系列便捷功能,让古籍的整理研究成果突破学术圈的壁垒,成为滋养当代人思想与心灵的源头活水。
▲识典古籍官网首页截图。
数字化迁移的关口
“惟殷先人,有册有典”。中国是世界上产生书籍最早的国家之一,从早期的铭文和竹简到后来的抄本、印本,古籍保证了中华文化的源远流长、传承不息。从孔子删定“六经”始,汉代刘向父子校理群书,魏晋隋唐间对诸经的注疏,宋明时期大型类书如《太平御览》《永乐大典》等的编纂,到清人编定《全唐诗》《全唐文》《四库全书》,历代读书、刻书、藏书人为古籍的修旧起废、变通传承付出了艰苦努力。到了多媒体的电子阅读时代,当大批古籍因年代久远而纸散字碎,成为图书馆里无人翻动的文物,如何唤起对经典的记忆变得尤为迫切。
作为非再生性的文化遗产,以纸质形式存在的古籍是十分脆弱的。北京大学数字人文研究中心副主任杨浩介绍,由于各类天灾人祸,比如水火灾害、战争兵燹的损毁,许多古籍都消失在了历史长河中,能保存下来的一般都是有许多抄本与刻本的古籍。这些幸存的古籍如今大多被保存在图书馆、博物馆里,少数为私人收藏,每一次翻阅扫描都不可避免地会对其造成损害,“许多甚至一触即碎”。但如果任其躺在书架上,不被整理、阅读,就无法最大程度挖掘古籍的文献史料价值,尤其是那些冷门的古籍终将随着纸质形态的消亡而消失在大众记忆中。

▲珍藏在图书馆内的古籍。(新华社记者毛思倩/摄)
古籍的数字化一定程度上解决了古籍保护与利用之间的矛盾。它指运用计算机技术将语言文字或图形符号转化为能被计算机识别的数字符号,从而制成古籍文献书目数据库或古籍全文数据库,属于古籍整理的范畴。
与西方国家20世纪70年代便发起的“古登堡计划”相比,国内书籍的电子化于20世纪八、九十年代才起步,各地图书馆纷纷展开古籍的数字化工作,将古籍翻拍成电子图像。随着技术的不断进步,古籍的数字化也从简单的影像扫描升级为具备全文检索和超链接功能的古籍数据库,既能避免对古籍原本的直接使用,符合古籍保护的要求,又能随时随地调取古籍中的文本,并通过关键词的检索打通古今、连通各地、实现文献的零散到聚合,提高古籍的利用效率。当以一种整体性的眼光去回望那些卷帙浩繁的古籍,中华文明的来路、去处也变得更加清晰、有迹可循。
有学者认为,回顾历史,古籍经历了三次重要变化:一是汉晋时期,纸质书籍逐渐取代竹帛的地位;二是五代北宋以来,册印书籍逐渐取代手抄书;三是清末民初,机器印刷书籍取代手工雕版印刷。如今,古籍再次面临数字化的关口,那些物质形态的书籍可以被无限复制,在数字空间中获得永生。北京大学数字人文研究中心主任王军认为,“将历经数千年残存的中华典籍迁移到数字环境下是当代人的历史责任。”
AI技术引进古籍整理
然而,建立古籍数字化数据库是一个庞大的工程。资金缺口大、技术难度高、专业人才的缺乏一直是古籍数字化项目的痛点。
中国是世界上保存古籍文献最为丰富的国家,据不完全统计,中国现存古籍总量约5000余万册(件),共计26 余万种,然而其中只有8万种实现了数字化影像扫描,这8万种当中又只有3~4万种实现了文本数字化,平均每年500多种。按照这一速度,实现全部现存古籍文本数字化大概需要两三百年。
若利用人工智能技术辅助修复整理,这一年限大概能缩短至二三十年。据介绍,2012年是人工智能技术大爆发的一年,美国斯坦福的计算机科学家研发的ImageNet计算机视觉系统识别项目标志着人工智能在图像识别方面取得巨大突破;2018年谷歌发布的BERT模型在机器阅读理解顶级水平测试中取得惊人成绩,使得自然语言处理技术突飞猛进……这些成果很快引起了学界的注意,他们尝试借助人工智能的东风,让那些“停留在金石、竹简和纸张上的先哲智慧也能够插上数字化的翅膀。”
成立不到两年的北京大学数字人文研究中心便是国内为数不多的利用人工智能进行古籍数字化的学术机构。近期上线的“识典古籍”便是该研究中心与字节跳动科技公司合作研发的古籍数字化公益平台,它整合了北京大学古籍数字化的学术资源与字节跳动的技术力量和平台优势,也诠释了以大数据、人工智能等为代表的信息技术如何为古籍的保护与传承注入新的活力。
点击“识典古籍”网站首页,读者能看到《论语》《孟子》《礼记》等各类经典陈列于“架”上,随意点开一本,左侧为书的章节目录,右侧为正文。为了打造一个对一般大众友好的古籍阅读平台,设计者从页面排版到功能设置都致力于降低阅读门槛,在顺应现代人阅读习惯的同时还原古籍纸张阅读的美感。

▲通过原本影像和古文的左右对照,读者可以用现代人习惯的方式顺畅阅读古籍,也能感受古籍原貌。
点击右上方“原本影像”,读者可查看古籍的底本影印图像,图文对照使读者既能浏览古籍原貌,又能顺畅地读懂古籍内容;点击繁简体转换功能,可轻松切换繁简字,在正文中,人名、地名、官职、书籍等专有名词以虚线方式标注了出来,方便专业研究人员、古籍爱好者以更加高效便利的方式读懂古籍内容。此外,读者还可以通过关键词检索,快速找到来自不同古籍的相关内容,方便大家对文献内容进行灵活运用。

▲“识典古籍”平台还具备繁简转换功能。
“目前,平台已经整理上线了460余部经典古籍,共计8000万字左右,主要来自《四部丛刊》;预计在3年内,我们将完成10000种古籍数字化整理,正准备上线的,还有道教典籍与佛教典籍等,对全社会免费开放。”识典古籍相关负责人介绍,平台的古籍数字化整理主要运用了3项人工智能技术:文字识别、自动标点、命名实体识别。

▲左侧为古籍原图,右侧为文字识别过程演示。
文字识别(即OCR技术)首先将单个文字从古籍影印图像中一个个切割开,再将切分好的图片送入模型,识别出具体文字,最后结合文字内容和文字位置获取阅读顺序,完成文字的识别;自动标点技术通过算法,给原本缺少断句的古籍自动打上标点符号。文字识别步骤中被识别出的文字,利用模型计算出每一个汉字之间标点的概率以及具体标点的类型,文字被打上标点并输出;为了增强阅读体验,命名实体识别技术会通过预测文字的实体标签,识别包括人名、地名、书籍、时间、官职五种类型的专有名词。
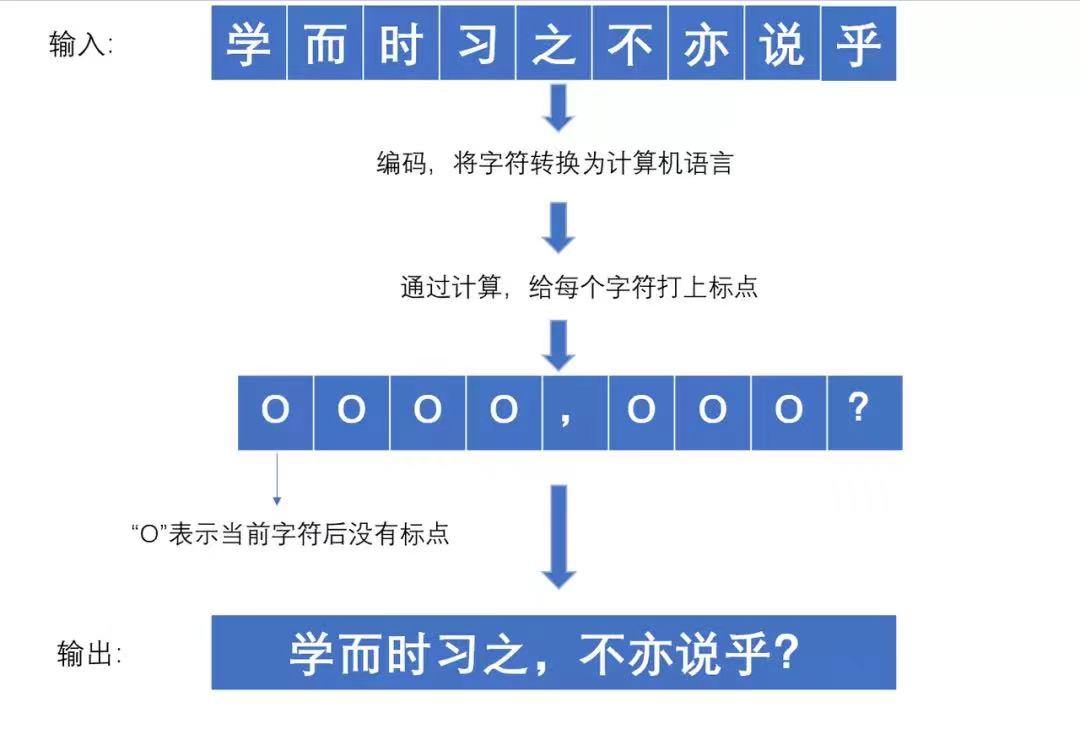
▲古籍自动标点过程演示。

▲命名实体识别技术能识别包括人名、地名、书籍、时间、官职五种类型的专有名词。
据介绍,北京大学数字人文中心对这一数字平台的期许是,通过人工智能技术,实现全自动整理校对,更高效地实现存量古籍全部数字化。在文本数字化的基础上,他们还希望对文本做“结构化的数据提取”,将古籍所蕴含的历史文化知识关联起来,建构起系统性的知识图谱,甚至实现智能化的人机知识问答。比如被认为理学重要奠基者的程颢程颐曾师从理学开创者周敦颐,二程的学说又影响了理学的集大成者朱熹,他们各自的生平、著述、学派等碎片化信息被系统性整合到一起,构建起一幅脉络清晰的知识网络,使得理学的发展历程一目了然。甚至实现智能化的人机知识问答。正如王军总结,智能时代古籍整理的目标应当是整理加工自动化、内容呈现可视化与知识关联全面化,这几个目标层层递进,相互关联。
这依然任重道远。虽然上述技术在近十年里有了巨大的进步,比如OCR技术识别准确率由5、6年前的70%左右提升到了现如今的90%以上,但对于排版复杂、“行与行之间十分密集”以及手抄本古籍,OCR技术的识别准确率依然不高,有些草书甚至根本无法识别。这意味着仍需要大量人力去完成古籍整理中繁琐、细碎的审校工作。这很耗神,眼力、脑力缺一不可。无论技术怎样变迁,古籍的保护与传承最依靠的还是那些心志不移的人。
北京大学数字人文研究中心目前核心成员有十几人,除了几位导师外,团队成员大多是研博生。他们分工明确,有人负责大数据文本分析,有人负责NLP技术的训练,有人负责写系统代码等。中心在这次合作中联合各大高校学者和文献专家,负责人工审核与校对,弥补人工智能有识别错误率的短板。除此之外,上百位志愿者也为“识典古籍”的建设付出了努力。
“这些志愿者很多都是仍在就读的大学生。”杨浩介绍,他们来自不同的学校、专业,都是一群“古籍爱好者”,“工作兴致很高”。在团队内部的古籍整理平台,志愿者们负责对技术处理后的文本进行基本的文字、标点校对,经过类似“三审三校”的流程,将整理后的古籍导入“识典古籍”平台上,供大众浏览。
“我们做这个平台也希望能起到一个模范带头作用,把热爱古籍的人聚集到一起,让古籍公益事业的人气能够上涨。”“识典古籍”的相关负责人表示。
提供当代人的精神养料
在阅读习惯已被新媒体大大改造,层出不穷、样式新奇的文本分割并抢夺注意力的当下,除了初高中课本里那几篇耳熟能详的古诗文,让大多数人感到陌生、疏离乃至畏惧的古籍很难突破学术圈的壁垒,走进一般读者的视野。
但实际上,古籍并非就如古化石一样与当代生活格格不入,恰恰相反,那些古文名篇中描述的风景与心情在千百年后的我们读来依然历历在目、感同身受。古文对我们生活感受、思维方式的塑造,早已渗透在我们脱口而出的成语、习语和典故中。杨浩说,如果认真去读古人的著作,你会发现我们现在困惑的一些问题,古人早已思考过,他们对生命的感受与思考甚至比今人更深刻。
如何融媒体环境下推动典籍的大众阅读?王军提出,除了对古籍的原生性保护和数字化再现,还要有典籍内容的释读,面向大众的再创作与再阐释。“这种重新阐释不是一字一句去翻译,而是要跟当代人生活结合在一起,为我们当代人精神提供养料,这样才能真正实现活化。”

▲古籍修复照。(新华社记者周牧/摄)
当代融媒体环境为典籍的大众诠释提供了更多样、生动的可能。正如前段时间热播的《典籍里的中国》以及字节跳动联合中国文物保护基金会、国家图书馆发起“寻找古籍守护人”活动等,研究古籍保护的学者、古籍修复专家以及不同行业的古籍爱好者们在镜头前解读经典古籍,讲述古籍保护的故事,声色并茂的讲述进一步拉近了古籍与大众的距离。
王军说,儒家文化一直有着口头传承史,比如《论语》是孔子与弟子间的问答记录;魏晋时期讲诵经学盛极一时;北宋时期《二程语录》与南宋时期的《朱子语录》都是对口述的记录。他认为要引入学术资源,结合当代生活,对经典现代阐释。并以头条、百科、 抖音短视频、数字产品、 交互媒体等多种形态做立体传播,打造数字环境下典籍传承的全方位生态体系,为当代人提供心灵滋养和精神寄托。
民国时期,胡适等人曾提出“整理国故,再造文明”,王军认为放到今天的全球互联网语境下,“再造文明”意味着我们要将整理古籍这件事放到全球文明体系下来看待,“我们保护的不仅仅是中华文明,而是全人类的珍贵文化遗产,所以我们要放在这个大的文明体系下来重新审视我们自己的文明。就像胡适这一批知识分子说的,典籍的重新整理不仅要连接过去与现代,而且要沟通东方和西方,否则就变成一种孤芳自赏。”
在研发团队的设想中,“识典古籍”不仅是一个数字阅读平台,依托互联网产品研发与设计能力优化古籍阅读与利用方式,未来平台还将鼓励拥有文献的学者自行上传文献,用户甚至可参与再创作和再阐释,让平台成为一个围绕古籍的网络社区空间。在古今碰撞中,那些蒙尘已久的文字或许会像河水一样重新流动起来,给当代人留下无穷无尽的余响。
作者:本报驻京记者 彭丹
图片:除标注外均受访者供图
编辑:江胜信
责任编辑:陆正明
*文汇独家稿件,转载请注明出处。
